Business Context
Understanding the real-world value and application
The Problem
- Traditional on-premises HPC clusters often suffer from rigid capacity constraints, leading to significant delays in scientific simulations and data processing due to long queue times and underutilized resources during off-peak periods.
- Managing and scaling complex HPC environments, including job schedulers, file systems, and interconnects, requires specialized expertise and substantial operational overhead, diverting valuable research time.
- Data-intensive scientific workloads frequently encounter I/O bottlenecks with conventional storage solutions, hindering the performance of applications that rely on rapid access to large datasets.
The Solution
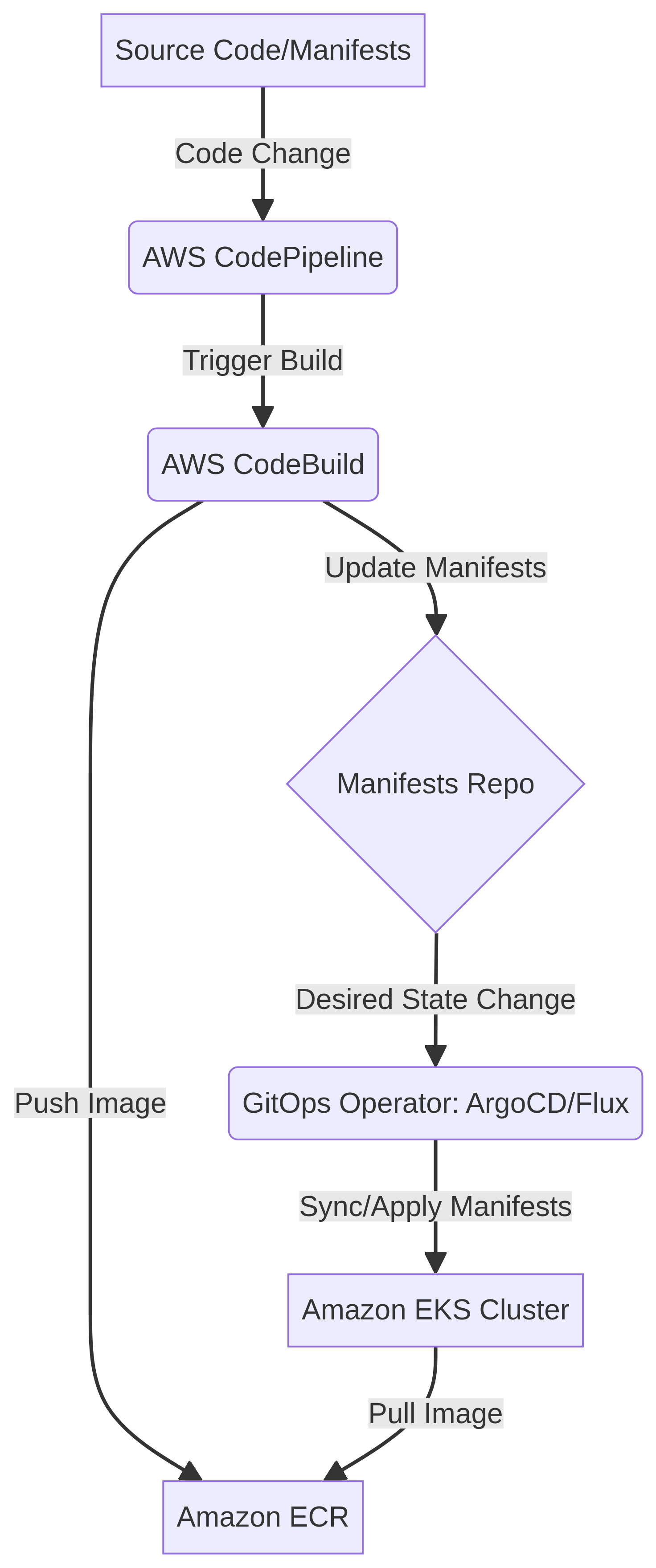
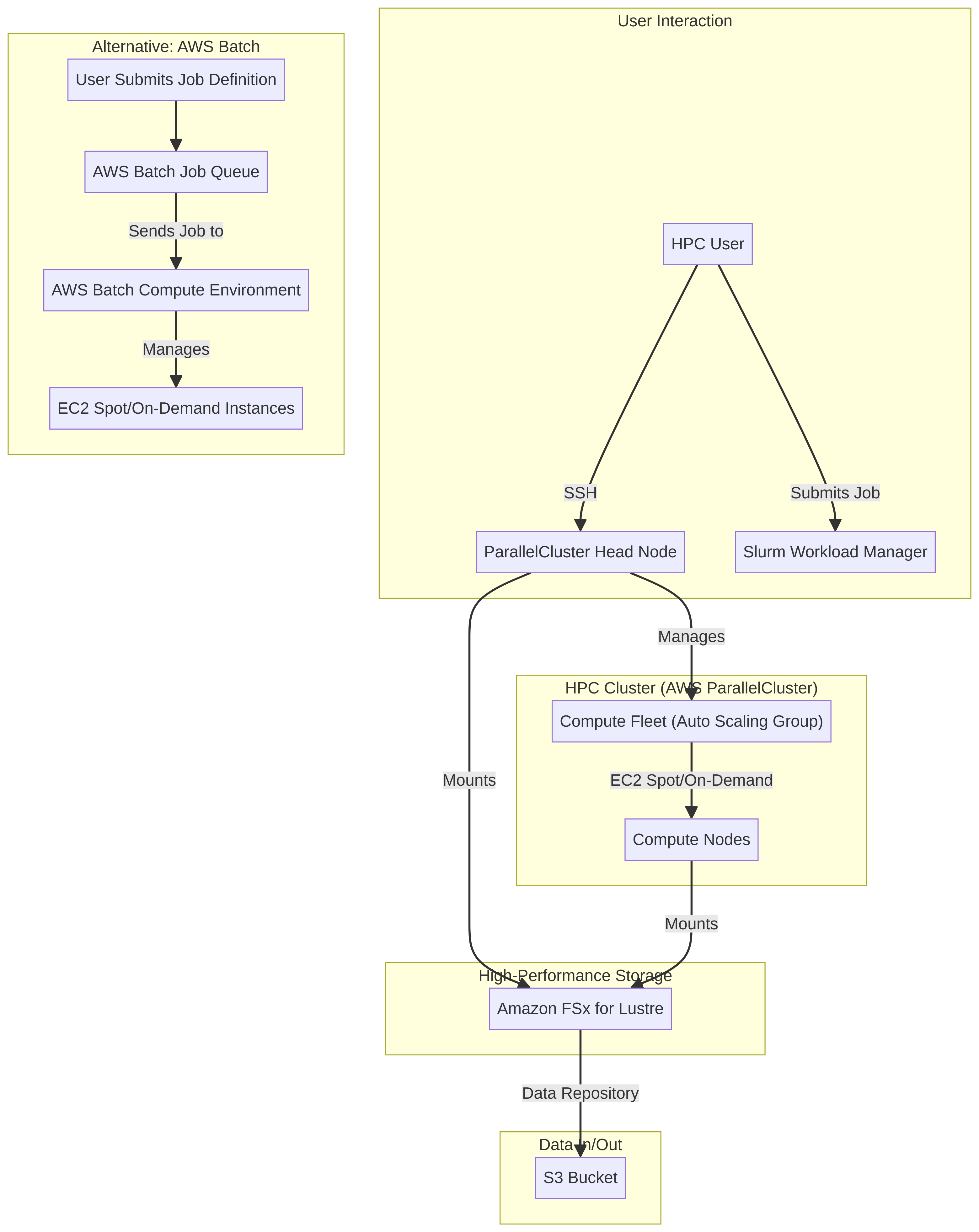
- Implements a scalable HPC infrastructure using AWS ParallelCluster to automate the deployment and management of compute environments tailored for scientific workloads.
- Leverages AWS Batch for efficient, dynamic job scheduling and execution, ensuring optimal resource utilization and reduced wait times for computational tasks.
- Integrates Amazon FSx for Lustre to provide high-performance, POSIX-compliant file storage, eliminating I/O bottlenecks for data-intensive applications.
Business Value
- Accelerates research cycles by 40% through on-demand access to HPC resources, reducing simulation run times from days to hours.
- Decreases infrastructure operational costs by 30% by transitioning from fixed capital expenditure to a pay-as-you-go cloud model.
- Increases computational throughput by 50% during peak demand periods, enabling more concurrent scientific experiments and analyses.
- Achieves 99.9% availability for HPC workloads, minimizing disruptions to critical research and development initiatives.
Risk Mitigation
- Mitigates the risk of resource starvation and project delays by providing elastic scaling of compute resources to match fluctuating demand.
- Reduces the risk of data loss and corruption through automated backups and highly durable storage solutions offered by AWS.
- Addresses the risk of security vulnerabilities by implementing AWS best practices for network isolation, access control, and data encryption.
- Minimizes operational complexity and human error through infrastructure as code (IaC) and automated management provided by AWS ParallelCluster.
{kind=link}