Business Context
Understanding the real-world value and application
The Problem
- Traditional on-premise infrastructure struggles to provide the scalable compute resources necessary for distributed training of large, complex machine learning models, leading to prolonged training times and inefficient resource utilization.
- Managing diverse ML frameworks and dependencies across different training environments creates significant operational overhead and introduces inconsistencies, hindering reproducibility and collaboration among data science teams.
- Lack of integrated monitoring and logging for custom training jobs makes it difficult to debug failures, track performance metrics, and ensure the reliability of experimental and production models.
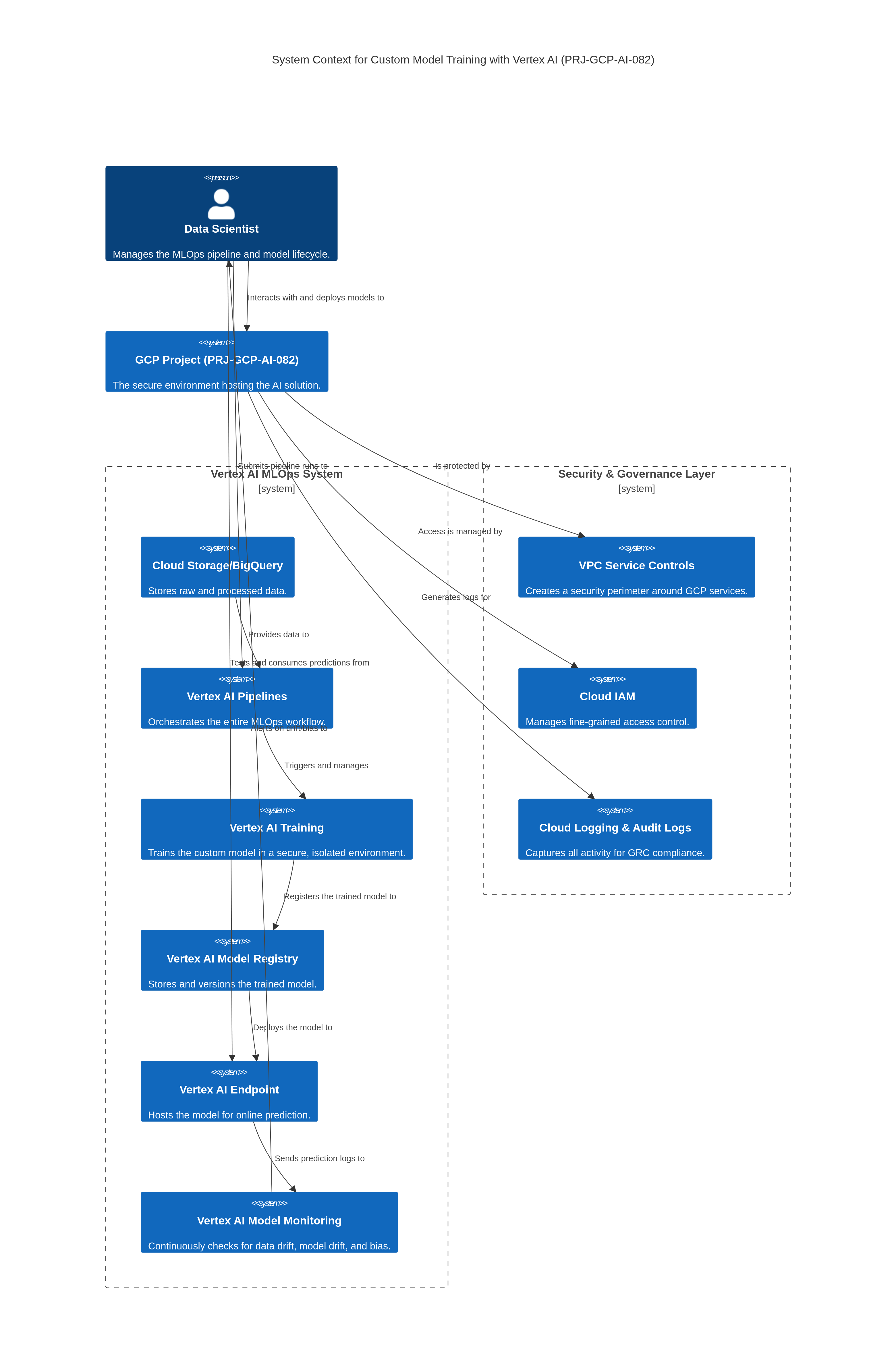
The Solution
- Leveraging Vertex AI Training to orchestrate distributed model training jobs, dynamically allocating and deallocating GCP compute resources (e.g., GPUs, TPUs) based on workload demands.
- Utilizing Custom Containers to encapsulate TensorFlow models and their dependencies, ensuring consistent and reproducible training environments across development, testing, and production.
- Implementing integrated logging and monitoring within Vertex AI Training to provide real-time insights into training progress, resource consumption, and model performance metrics.
Business Value
- Reduces model training time by an average of 40%, accelerating the development and deployment of new AI features.
- Increases data scientist productivity by 25% through streamlined environment management and automated resource provisioning.
- Achieves a 99.9% success rate for distributed training jobs, minimizing costly re-runs and ensuring reliable model delivery.
- Decreases infrastructure operational costs by 30% through optimized resource scaling and pay-per-use billing for compute.
Risk Mitigation
- Mitigates vendor lock-in by using open-source TensorFlow within Custom Containers, allowing for portability across cloud providers if needed.
- Reduces data exfiltration risk during training by ensuring all data processing occurs within the secure GCP environment, adhering to Google's robust security protocols.
- Addresses model drift and performance degradation risks through continuous monitoring and automated retraining pipelines facilitated by Vertex AI Training.
- Minimizes configuration errors and environment inconsistencies by standardizing training environments via Custom Containers.